
ファイルのデータサイズを仕分けてみる [LinuxでSoftware RAID]
RAIDを構成する際の参考として、chunk sizeをいろいろと変えて
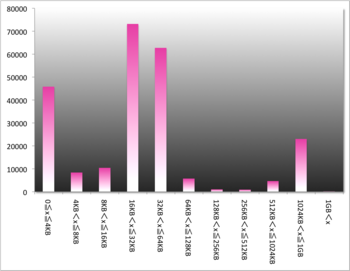
ベンチマークを取ってみましたが、まぁ、あまり変わらなかった訳です![[たらーっ(汗)]](https://blog.ss-blog.jp/_images_e/163.gif)
そもそもchunk sizeとはLinuxのSoftware RAIDで一度に取り扱う
データブロックのサイズのことを表します。
ファイルシステムとしてのブロックサイズとはまた別です。
最近はext4とかでフォーマットするとデフォルトでは4096Byteが
ブロックサイズとして使われるようです。
# tune2fs -l /dev/md0 などで調べられます。
ですので、chunk sizeは4KB以上で設定し、読み書きスピードや
無駄があまり出ないサイズに設定するのがよさそうです。
とすると、一体、普段ファイルサーバに保存しているデータのサイズは
いかほどに?という疑問がわいてきますので、調べてみました。
今、ファイルサーバは再構築中なので全てのデータはiMac上に
待避中です。
なので、OSXのターミナルからファイルサーバで保存している
ファイルの一覧を取得し、エクセルでちゃちゃっとヒストグラムを
作ってみます。
$ find ./Desktop/St1 -type f -exec ls -la {} \; >> volume.txt
対象とするフォルダ ./Desktop/St1
にあるファイルだけを抽出して、
volume.txtに書き出します。
ls- la コマンドで出力される情報がそのまま出てきますので、
ファイルサイズ以外の情報を削除して、エクセルのfrequency()関数で、
頻度を抽出します。
あまり細かく分けても仕方ないので、わりとおおざっぱです。
ls- la の結果はbyte単位で出力されているので、
| 4000 |
| 8000 |
| 16000 |
| 32000 |
| 64000 |
| 128000 |
| 256000 |
| 512000 |
| 1024000 |
| 1024000000 |
| 1.024E+12 |
| 1.024E+15 |
この12段階に分けます。
結果、こんな感じ。
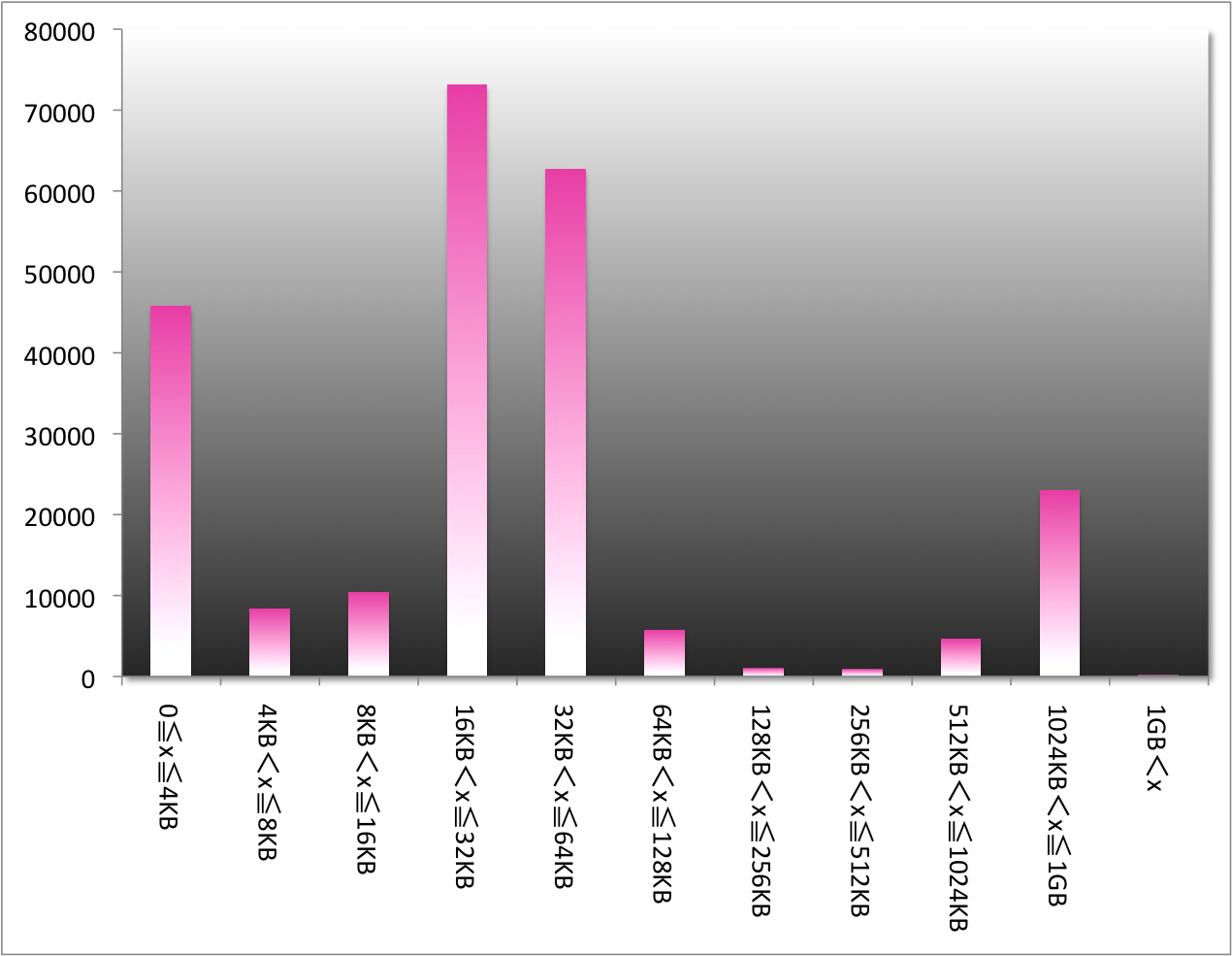
横軸:ファイルサイズグループ(x)
縦軸:個数
ほとんどのデータが16KB~64KBに集まっていることがわかります。
ですので、ハードディスクの無駄使いを抑えるためには、
chunk size を16KBに設定するのがよさそうですが、一方で、
16KBだと1chunk? に入りきらないので、2~4chunk使うことに
なり、読み書きの効率が悪そうです。
1chunkに納めるためにはchunk sizeを64KBに設定すると、
85%以上のデータが1Chunkに収まることになり、効率は
良さそうです。
ところで、chunk size = 64KB はデフォルト値です。
やっぱり、「デフォルト最適説」がまた検証されました![[晴れ]](https://blog.ss-blog.jp/_images_e/1.gif)
nao さん

-
nice! 59
記事 248
テーマ パソコン・インターネット (20位)
プロフィール
ブログを紹介する


